Managing and migrating large-scale datasets is no small feat. Recently, we faced the challenge of working with 8 billion rows(10 terabytes) of data stored in Azure Data Lake Gen2, spread across 60,000 CSV files. Our mission was to organize, clean, transform, and move this data into Azure SQL for analytics and reporting. Here’s how we tackled it step by step, leveraging a combination of Azure Synapse Pipelines and SQL scripting to achieve this monumental task.
The Challenge
The raw data in Azure Storage was a massive, unstructured collection of CSV files. These files represented 2 months of records but were not organized by date or other logical partitions.
Our goals included:
- 1. Organizing the data by processing it into daily partitions for efficient management.
- 2. Loading the data into Azure SQL in a structured format.
- 3. Performing data cleanup, deduplication, and extraction during the migration.
- 4. Ensuring the process was scalable and could handle the size of the data without breaking.
The sheer volume of data — 8 billion rows across 60,000 files — meant that traditional manual processing or single-step pipelines would not suffice. We needed an efficient, automated, and fault-tolerant approach.
Things we have tried before the working approach:
- We tried to dump all the data to an sql table to process later. We applied all the tactics: paralellization, disabling indexing and clustering before huge data load etc. It was successful all the data(8 billion rows) was in single sql table. Single unusable sql table because it was impossible after that to do any processing or transformation on that table.
- If you disable all the indexes and partitioning pre-load to make faster load; later it becomes impossible to re-index the 8 billion rows. if you enable indexes at the beginning then the initial data load takes forever.
So how we solved the problem; don’t load all the data and transform. Separate it into chunks and do transfer + transform chunk by chunk(this is different from transfer chunk bu chunk then transform all).
Step 1: Organizing the Data with Azure Synapse Pipelines
The first hurdle was organizing the raw data into day-wise partitions for easier processing. For this, we used Azure Synapse Pipelines, a robust tool for data integration and orchestration in Azure.
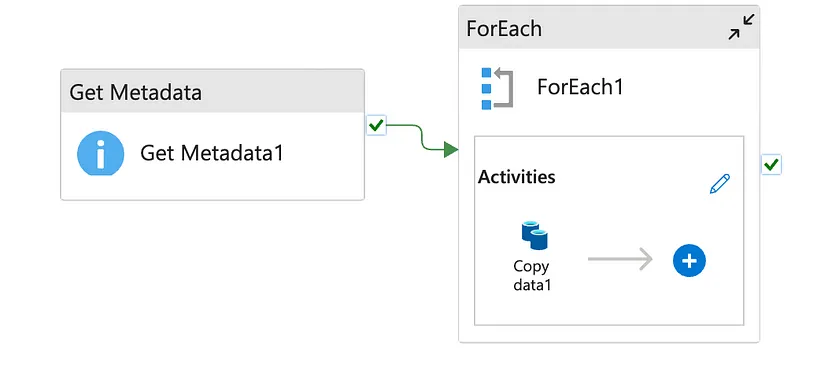
Synapse Pipeline to divide data into chunks on Azure Data Lake Gen2
Extracted Metadata:
We scanned the raw CSV files in the data lake to extract relevant metadata, such as timestamps from the file contents. This allowed us to determine the date associated with each file.
Partitioned the Data:
Using Synapse Pipelines, we created a data flow that read the CSV files, extracted their records, and wrote them into date-based folders in Azure Storage (e.g., /data/YYYY-MM-DD/). This partitioning was critical for efficient processing downstream.
Automated the Workflow:
A Synapse pipeline was configured to run in parallel, processing multiple files simultaneously. This allowed us to handle thousands of files in a scalable manner.
The Outcome
By the end of this step, we had organized all 60,000 files into daily partitions. Each folder in Azure Data Lake now contained the records for a specific date, making it easier to process and manage the data incrementally.
Step 2: Loading Data into Azure SQL
Once the data was partitioned, the next challenge was loading it into Azure SQL. For this, we used Azure SQL’s COPY INTO functionality to ingest the CSV files efficiently. (Note: Azure SQL’s copy into support from data lake is faster than anything else(data factory pipelines included) we tried).
Dynamic Ingestion Script:
We wrote a SQL script that dynamically generated COPY INTO commands to load each day’s data into a corresponding staging table in Azure SQL.
Batch Processing:
The script iterated over all date-based partitions, loading data day by day. This avoided overwhelming the system and allowed us to monitor progress.
Error Handling:
The script was designed to skip missing or corrupt files, ensuring the process continued without interruption.
Step 3: Cleaning and Transforming the Data
With the data loaded into staging tables, we turned our focus to data transformation and cleanup.
Dropped Unnecessary Columns:
Many columns in the raw data were irrelevant for analytics. Using dynamic SQL, we dropped these columns to save storage and improve query performance.
Removed Invalid Rows:
Rows with invalid timestamps or irrelevant parameters were deleted to ensure data quality.
Eliminated Duplicates:
Using SQL’s "ROW_NUMBER" function, we identified and removed duplicate rows based on business logic.
Step 4: Dynamic and Scalable Automation
One of the key challenges was handling such a large dataset dynamically and at scale. To achieve this:
Dynamic SQL:
The SQL scripts were built dynamically to process each day’s data, allowing the process to adapt to the data structure.
Column Existence Checks:
We checked for the existence of columns before performing operations, ensuring that missing columns didn’t interrupt the workflow on re-runs.
Parallel Execution:
Where possible, we executed parts of the workflow in parallel to reduce processing time.
Step 5: Key Learnings
This project reinforced several important lessons:
Partitioning is Key:
Breaking large datasets into manageable chunks, such as daily partitions, simplifies processing and improves performance.
Automation Saves Time:
Writing robust scripts and pipelines for automation reduces manual effort and minimizes errors.
Flexibility Matters:
Dynamic SQL and flexible workflows ensure that the process adapts to data changes without requiring constant updates.
The Results
Through this structured approach:
- We processed and organized 8 billion rows of raw data.
- Partitioned them into daily folders in Azure Storage.
- Loaded the data into Azure SQL while performing cleanup, transformation, and deduplication.
- Extracted key user insights into a separate table for analytics.
This scalable, automated process allowed us to handle massive data volumes efficiently, setting the foundation for advanced analytics and reporting.
Conclusion
Handling large-scale data migration requires a blend of robust tools, careful planning, and scalable solutions. By combining Azure Synapse Pipelines for data partitioning with Azure SQL for processing and transformation, we successfully migrated billions of rows without breaking a sweat. Whether it’s for analytics, machine learning, or operational reporting, this approach ensures your data is ready to drive value.


